Los embeddings son la infraestructura invisible que hace que los LLMs entiendan el lenguaje. No son el modelo en sí, ni el prompt, ni el contexto. Son la capa que convierte texto arbitrario (una factura, un manual técnico, un fragmento de contrato) en un vector numérico que un sistema puede comparar, buscar y razonar. Sin embeddings, no hay RAG funcional. Sin RAG funcional, los agentes de IA para empresas no tienen memoria semántica a largo plazo. Entender cómo funcionan los vectores semánticos no es un detalle académico: es la diferencia entre un sistema que recupera el fragmento correcto y uno que alucina.
Este post cubre todo lo que un AI engineer necesita saber sobre embeddings: cómo se generan desde el tokenizer hasta el espacio vectorial, qué significa la dimensionalidad, por qué cosine similarity funciona mejor que la distancia euclidiana en alta dimensión, qué modelos usar en producción (OpenAI, Voyage, Cohere, open-source), cómo adaptarlos a un dominio específico con fine-tuning, y código ejecutable para cada etapa. Si estás construyendo un pipeline de retrieval augmented generation o evaluando qué base de datos vectorial elegir, este es el punto de entrada.
Este post es para developers y AI engineers que ya saben qué es un LLM y buscan profundidad operativa, no para quien está descubriendo la IA por primera vez. El nivel de referencia es la documentación oficial de OpenAI o el repositorio de Sentence Transformers. Si buscas cómo configurar un chatbot sin código, este no es tu artículo.
Tabla de contenidos
- ¿Qué son los embeddings y por qué son la base de RAG?
- Cómo se generan: del tokenizer al espacio vectorial
- Dimensionalidad: 768, 1536, 3072 — qué elegir
- Similarity: cosine, dot product, euclidean
- Modelos comparados: OpenAI vs Voyage vs Cohere vs open-source
- Embeddings multilingües y específicos de dominio
- Implementación: generar + almacenar + buscar
- Fine-tuning de embeddings con tu propio dataset
- Preguntas frecuentes sobre embeddings
- Conclusión
¿Qué son los embeddings y por qué son la base de RAG?
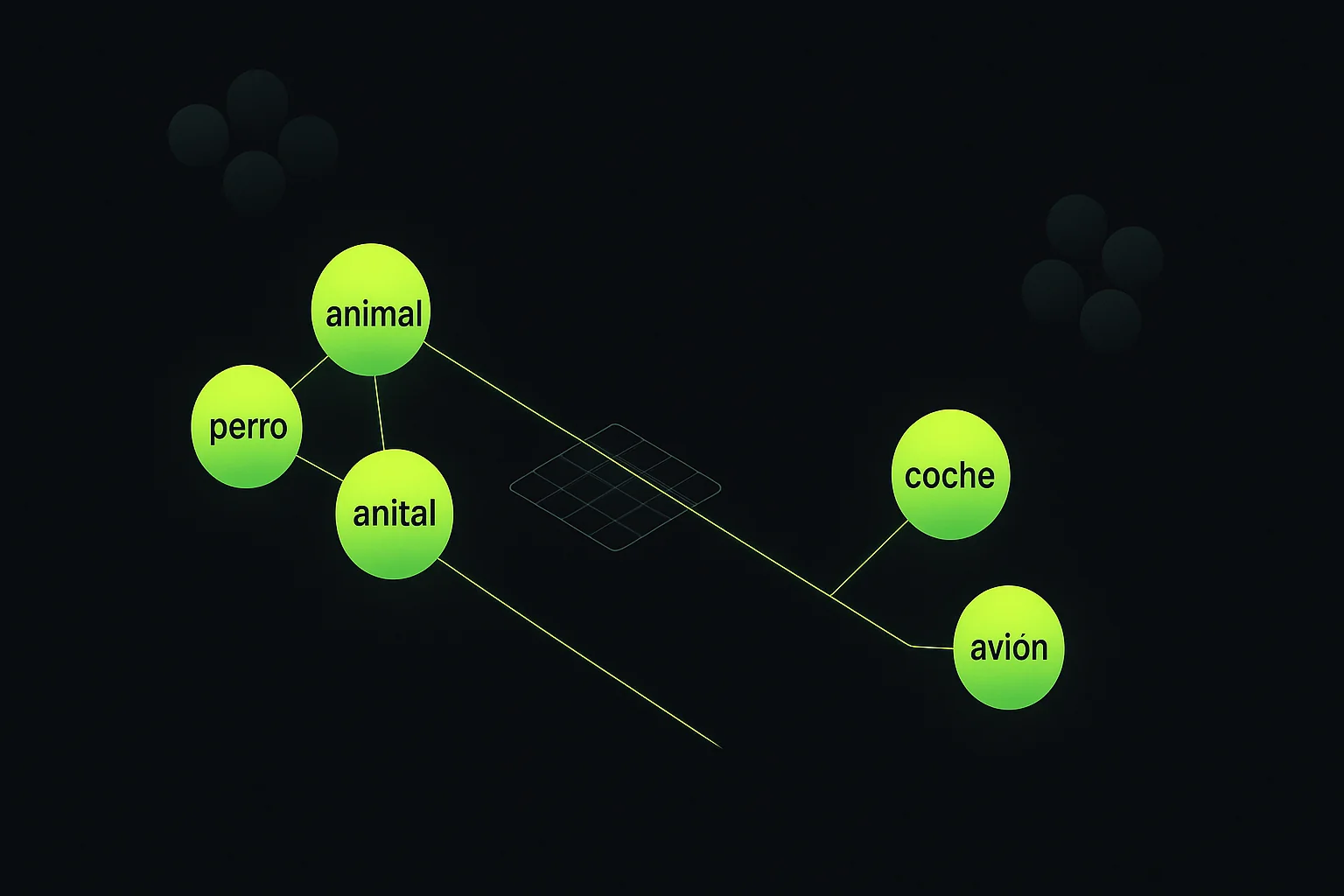
Un embedding es una representación densa de un texto en un espacio vectorial de alta dimensión. En términos prácticos: tomás una cadena de texto, una frase, un párrafo, un documento entero y un modelo de embeddings la convierte en un array de números de punto flotante, normalmente entre 768 y 3072 valores. Ese array es el embedding. La propiedad fundamental que lo hace útil es que textos semánticamente similares producen vectores cercanos en ese espacio, independientemente de si comparten palabras exactas.
La distinción entre embeddings y representaciones anteriores como TF-IDF o BM25 es crítica. TF-IDF mide co-ocurrencia de términos: si buscas «cancelar suscripción» y el documento dice «dar de baja el contrato», TF-IDF no ve similitud porque no hay términos en común. Un embedding semántico sí detecta que ambas frases expresan el mismo intent. Esa capacidad de capturar significado por encima de la superficie léxica es lo que hace los embeddings imprescindibles en cualquier sistema de búsqueda moderna.
Por qué RAG depende de embeddings de calidad
En un pipeline de retrieval augmented generation, el flujo básico es: dividir el corpus en chunks, generar un embedding por chunk, almacenarlos en una base de datos vectorial, y en tiempo de query generar el embedding de la pregunta y recuperar los chunks más cercanos. El LLM solo ve esos chunks recuperados más el historial de conversación. Si el modelo de embeddings es mediocre, recuperará chunks irrelevantes y el LLM generará respuestas incorrectas aunque sea GPT-4o. La calidad del retrieval limita el techo del sistema, no la calidad del generador. Este punto es frecuentemente subestimado en implementaciones de producción.
La elección del modelo de embeddings también impacta directamente en el coste operativo. Un modelo de 1536 dimensiones almacenado como float32 ocupa 6KB por vector. Con un corpus de 500.000 chunks, eso es ~3 GB en RAM solo para los vectores. Pasar a float16 lo reduce a la mitad con pérdida mínima de calidad en la mayoría de casos. La base de datos vectorial que elijas condiciona qué tipos de cuantización puedes aplicar. Estas decisiones hay que tomarlas con el brief de producción sobre la mesa, no a posteriori.
Embeddings de texto vs. embeddings multimodales
Los embeddings más comunes en pipelines empresariales son de texto, pero la familia es más amplia. CLIP (OpenAI, 2021) generó embeddings en un espacio compartido imagen-texto, lo que permite buscar imágenes con queries textuales. Los embeddings de código, como los usados por GitHub Copilot, son entrenados sobre datasets de código y capturan similitud funcional entre snippets. Los modelos de embeddings de audio permiten búsqueda semántica en podcasts o llamadas. Para el caso de uso de la mayoría de empresas —búsqueda en documentación interna, contratos, emails, FAQs— los embeddings de texto son la herramienta correcta. Este post se centra exclusivamente en esa categoría.
Cómo se generan: del tokenizer al espacio vectorial
Para entender por qué un embedding tiene las propiedades que tiene, hay que rastrear el proceso desde el texto en bruto hasta el vector final. El pipeline tiene tres etapas: tokenización, paso por el encoder, y pooling del output.
Tokenización: la entrada al modelo
El texto nunca entra al modelo como caracteres o palabras enteras. Pasa primero por un tokenizer que lo convierte en una secuencia de token IDs. Los tokenizers modernos usan Byte Pair Encoding (BPE) o WordPiece. BPE parte de caracteres individuales y fusiona iterativamente los pares más frecuentes hasta alcanzar un vocabulario de tamaño fijo (típicamente 30.000-100.000 tokens). El resultado es que palabras comunes son un solo token, mientras que palabras raras o técnicas se dividen en subunidades. «embedding» puede ser un solo token; «embeddings» puede ser dos. Esta fragmentación tiene consecuencias directas sobre cómo el modelo representa conceptos técnicos poco frecuentes en su corpus de entrenamiento.
Cada token ID se mapea a un vector de embedding de entrada (token embedding) que vive en la primera capa del modelo. Estos token embeddings iniciales son parámetros aprendidos durante el preentrenamiento: el modelo ajusta estos vectores para que tokens semánticamente relacionados queden cercanos. A estos se suman los positional embeddings, que codifican la posición de cada token en la secuencia, dando al modelo información sobre el orden.
El encoder transformer: atención y representaciones contextuales
La secuencia de token embeddings pasa por N capas de un encoder transformer. Cada capa aplica multi-head self-attention: cada token «mira» a todos los demás tokens en la secuencia y actualiza su representación en función de cuáles son relevantes para entenderlo en ese contexto. La palabra «banco» tiene representaciones diferentes en «fui al banco a sacar dinero» y en «me senté en el banco del parque» porque la atención capta el contexto de las palabras circundantes.
Tras N capas de atención y feed-forward, cada token de la secuencia tiene un vector contextual de D dimensiones (donde D es la dimensión hidden del modelo). Para obtener un único vector que represente el texto completo, se aplica pooling. Las estrategias más comunes son: CLS token pooling (usar el vector del token especial [CLS] prepuesto a la secuencia, común en BERT) y mean pooling (promediar los vectores de todos los tokens, común en modelos más modernos como los de Sentence Transformers). El pooling con media suele superar al CLS pooling en benchmarks de semantic similarity para la mayoría de tareas.
Proyección final y normalización L2
Algunos modelos añaden una capa de proyección lineal sobre el output del pooling para reducir la dimensionalidad o adaptar el espacio vectorial al objetivo de la tarea (por ejemplo, maximizar similitud entre pares equivalentes). El vector resultante suele normalizarse con normalización L2 (dividir por su norma), lo que lo coloca sobre la superficie de una hiperesfera unitaria. Esta normalización tiene una consecuencia práctica importante: con vectores L2-normalizados, la similitud coseno es equivalente al producto punto, lo que permite usar FAISS y otras librerías que optimizan el dot product y lograr el mismo resultado semántico con operaciones más rápidas.
Dimensionalidad: 768, 1536, 3072 — qué elegir
La dimensionalidad de un embedding —el número de valores en el vector— es uno de los hiperparámetros más influyentes en el balance entre calidad, coste de almacenamiento y latencia de búsqueda. No hay una respuesta universal. Aquí están los trade-offs reales.
768 dimensiones: el estándar BERT
768 dimensiones es el tamaño hidden de BERT-base y de la mayoría de modelos derivados de esa arquitectura. Modelos como all-MiniLM-L6-v2 usan 384 dimensiones (mitad de BERT-base), reduciendo el almacenamiento y la latencia de búsqueda a costa de algo de calidad. Para casos de uso donde el corpus es pequeño (<100.000 chunks) y los queries son cortos, 384 o 768 dimensiones son suficientes y más baratos en producción.
1536 dimensiones: el estándar OpenAI
text-embedding-3-small produce vectores de 1536 dimensiones. OpenAI también expone la capacidad de reducir la dimensionalidad mediante una simple truncación del vector: puedes pedir dimensiones menores (512, 256) y el modelo sigue siendo competitivo gracias a que fue entrenado con una técnica de Matryoshka Representation Learning (MRL), donde los primeros N valores del vector ya capturan la información más relevante. text-embedding-3-large llega a 3072 dimensiones y supera a 3-small en el benchmark MTEB en ~3 puntos de media, a un coste por token mayor.
Cuándo justificar 3072 dimensiones
Pasar de 1536 a 3072 dimensiones duplica el almacenamiento y el tiempo de búsqueda por fuerza bruta, pero con un índice HNSW en Qdrant o Weaviate la latencia de búsqueda real apenas varía para corpus menores de 10M vectores. La mejora de calidad en retrieval es notable en tareas de clasificación y búsqueda en dominios técnicos o científicos donde los matices semánticos son finos. Para una PYME con 50.000 documentos internos, el salto de 1536 a 3072 no justifica el coste adicional en la mayoría de casos. Para un sistema de búsqueda sobre literatura legal o médica con 5M documentos, sí puede marcar la diferencia en recall@10.
| Modelo | Dimensiones | MTEB (media) | Coste ($/1M tokens) | Caso de uso |
|---|---|---|---|---|
| text-embedding-3-small | 1536 | 62.3 | $0.02 | Producción general |
| text-embedding-3-large | 3072 | 64.6 | $0.13 | Alta precisión técnica |
| voyage-3 | 1024 | 65.1 | $0.06 | Retrieval optimizado |
| all-MiniLM-L6-v2 | 384 | 56.3 | $0 (local) | Prototipo / baja latencia |
| bge-m3 | 1024 | 63.5 | $0 (local) | Multilingüe open-source |
Similarity: cosine, dot product, euclidean
Una vez generados los embeddings, el retrieval se reduce a encontrar los vectores más cercanos al embedding del query. La métrica de similitud que uses afecta tanto el resultado como el rendimiento computacional. Hay tres candidatas principales.
Cosine similarity: la opción por defecto
La similitud coseno mide el ángulo entre dos vectores, ignorando su magnitud. Para vectores L2-normalizados, se calcula como el producto punto: sim = A · B. El resultado está en [-1, 1], donde 1 es idéntico, 0 es ortogonal y -1 es opuesto. Es la métrica más usada en búsqueda semántica porque es invariante a la escala: un documento corto y uno largo que hablen del mismo tema tendrán alta similitud coseno aunque sus magnitudes difieran mucho. La mayoría de bases de datos vectoriales usan cosine como default, y es el punto de partida correcto salvo que tengas una razón específica para cambiarlo.
Dot product: más rápido, con caveats
El producto punto (dot product) no normaliza por magnitud: sim = Σ(Aᵢ × Bᵢ). Si los vectores están L2-normalizados, es exactamente equivalente a cosine similarity. Si no lo están, favorece vectores de mayor magnitud, lo que puede correlacionar con documentos más largos o con tokens más frecuentes. FAISS y otras librerías optimizan búsqueda por dot product con instrucciones SIMD, siendo ligeramente más rápido que calcular cosine cuando los vectores no están prenormalizados. Usa dot product si tus embeddings salen prenormalizados del modelo y priorizas latencia mínima.
Euclidean distance: cuándo no usarla
La distancia euclidiana mide la distancia L2 en el espacio: dist = √Σ(Aᵢ - Bᵢ)². En baja dimensión funciona bien. En alta dimensión (512+) sufre la maldición de la dimensionalidad: las distancias entre puntos se homogenizan y el discriminador semántico se diluye. Además, es sensible a la magnitud, igual que el dot product sin normalizar. Para embeddings semánticos en dimensiones altas, la distancia euclidiana rara vez es la elección correcta. Aparece en algunos benchmarks de clustering donde se asume normalización previa, pero en retrieval semántico de producción, cosine es superior en casi todos los casos medidos en el benchmark MTEB.
Modelos comparados: OpenAI vs Voyage vs Cohere vs open-source
El ecosistema de modelos de embeddings es más fragmentado que el de LLMs generativos. A diferencia del mercado de completions, donde GPT-4 y Claude dominan con clara separación, en embeddings los modelos open-source como BGE-M3 o E5-mistral-7b compiten directamente con los de pago en benchmarks específicos. La elección correcta depende del caso de uso, el presupuesto y los requisitos de latencia.
OpenAI text-embedding-3: el seguro
text-embedding-3-small y text-embedding-3-large son los modelos más fáciles de integrar si ya usas la API de OpenAI. La ventaja principal no es rendimiento bruto (Voyage les supera en algunos benchmarks de retrieval), sino la simplicidad operativa: un solo proveedor, SLA garantizado, facturación consolidada. La característica de Matryoshka Representation Learning permite truncar dimensiones sin reentrenar, lo que da flexibilidad para ajustar coste/calidad en producción. El límite de contexto es de 8191 tokens, suficiente para chunks de 500-1000 palabras con holgura.
Voyage AI: optimizado para retrieval
Voyage surge de investigación académica en Stanford y sus modelos están explícitamente optimizados para retrieval, no para tareas genéricas. voyage-3 lidera varios sub-benchmarks de MTEB en recuperación de documentos y supera a text-embedding-3-large en recall@10 en datasets ingleses. Voyage publica evaluaciones detalladas por tipo de tarea. Sus modelos especializados —voyage-finance-2, voyage-law-2, voyage-code-3— son relevantes para dominios específicos donde un modelo generalista flaquea. El inconveniente es la dependencia de un proveedor más pequeño con menor track record de uptime.
Cohere Embed v3: multilingüe con compresión
Cohere Embed v3 introduce dos características diferenciadoras: soporte nativo para más de 100 idiomas (incluyendo catalán, euskera y gallego, relevante para empresas españolas) y int8 y binary quantization nativas desde la API. Devolver embeddings en int8 en lugar de float32 reduce el almacenamiento en 4x con pérdidas de calidad mínimas (<1 punto MTEB en la mayoría de tareas), lo que puede ser relevante si el corpus es masivo. Para pipelines mixtos inglés-español, Cohere Embed v3 es una opción sólida.
Open-source: bge-m3 y E5-mistral
Si la soberanía de datos es un requisito no negociable —sector sanitario, legal, administración pública— los modelos open-source son la única vía. BGE-M3 (BAAI, 2024) soporta más de 100 idiomas, admite textos de hasta 8192 tokens y produce embeddings de 1024 dimensiones. En el benchmark MTEB multilingual, supera a modelos propietarios en varios idiomas europeos. E5-mistral-7b-instruct (Microsoft) usa un LLM de 7B parámetros como encoder, lo que lo convierte en el modelo open-source más potente en benchmarks de inglés, a cambio de requerir una GPU con al menos 16 GB VRAM para inferencia razonable. En Hugging Face están disponibles con sus model cards y benchmarks detallados.
Embeddings multilingües y específicos de dominio
El contexto de baigency.com es España y LATAM: los pipelines de producción necesitan manejar español con calidad. Esto excluye modelos entrenados mayoritariamente en inglés sin datos multilingües suficientes, y plantea la cuestión de los embeddings específicos de dominio.
El problema del español con modelos anglocéntricos
Modelos como all-MiniLM-L6-v2 están entrenados predominantemente en inglés. En benchmarks de retrieval en español, su rendimiento cae entre 5 y 12 puntos respecto a su rendimiento en inglés. El problema no es solo la cobertura de vocabulario (el tokenizer puede tokenizar español correctamente), sino que los pares de entrenamiento de similitud usados para optimizar el modelo son mayoritariamente en inglés. El modelo no ha visto suficientes ejemplos de que «cancelar contrato» y «dar de baja el servicio» son semánticamente equivalentes en castellano. Para producción en español, la elección es BGE-M3, Cohere Embed v3, o text-embedding-3 de OpenAI (que tiene cobertura multilingüe razonable aunque no es su punto fuerte).
Embeddings específicos de dominio: cuándo construirlos
Un modelo de embeddings generalista puede no capturar la semántica específica de un dominio técnico. En derecho, «rescisión» y «resolución» tienen significados distintos aunque coexistan en contextos similares. En medicina, «insuficiencia» tiene múltiples acepciones. Si el retrieval sobre un corpus especializado muestra precision@10 por debajo del 70% con un modelo generalista, hay tres opciones: fine-tuning del modelo de embeddings, uso de un modelo especializado de pago (Voyage Finance, Voyage Law), o añadir un reranker que corrija el retrieval inicial.
Rerankers como complemento de los embeddings
Un reranker (modelo cross-encoder) recibe el par (query, documento) completo y asigna un score de relevancia más preciso que el embedding de dos torres. El flujo es: recuperar top-100 por similitud coseno con el bi-encoder (embedding), luego reordenar con el cross-encoder y quedarse con top-5. Modelos como Cohere Rerank o BGE Reranker v2-m3 son los más usados en producción. El coste es mayor (el reranker procesa N pares, no un solo vector) pero la precisión mejora sustancialmente en dominios complejos. En un pipeline de chunking bien diseñado, el reranker cierra la última brecha entre retrieval semántico y precisión real.
Implementación: generar + almacenar + buscar
Esta sección incluye cuatro bloques de código ejecutables que cubren el flujo completo: generación de embeddings con OpenAI, generación local con Sentence Transformers, comparativa de similitud entre frases, y fine-tuning. Los tres primeros son suficientes para un prototipo funcional en un fin de semana.
Code block 1: embeddings con OpenAI text-embedding-3-large
from openai import OpenAI
from typing import Union
client = OpenAI() # OPENAI_API_KEY desde variable de entorno
def embed_texts(
texts: list[str],
model: str = "text-embedding-3-large",
dimensions: int = 1536 # Matryoshka: reducir sin reentrenar
) -> list[list[float]]:
"""
Genera embeddings para una lista de textos.
Soporta batching automático hasta 2048 inputs por llamada.
"""
response = client.embeddings.create(
input=texts,
model=model,
dimensions=dimensions,
encoding_format="float" # o "base64" para reducir bytes en red
)
# El orden de response.data sigue el orden del input
return [item.embedding for item in response.data]
# Uso básico
chunks = [
"El contrato se rescinde automáticamente si el pago no se recibe en 30 días.",
"La factura debe abonarse en un plazo máximo de un mes desde su emisión.",
"El cielo de Madrid en junio es de un azul intenso.",
]
embeddings = embed_texts(chunks)
print(f"Dimensiones: {len(embeddings[0])}") # 1536
print(f"Vectores generados: {len(embeddings)}") # 3
Code block 2: embeddings locales con Sentence Transformers
from sentence_transformers import SentenceTransformer
import numpy as np
# BGE-M3: multilingüe, 1024 dims, contexto 8192 tokens
# https://huggingface.co/BAAI/bge-m3
model = SentenceTransformer("BAAI/bge-m3")
chunks = [
"El contrato se rescinde automáticamente si el pago no se recibe en 30 días.",
"La factura debe abonarse en un plazo máximo de un mes desde su emisión.",
"El cielo de Madrid en junio es de un azul intenso.",
]
# normalize_embeddings=True -> L2 normalization incluida
# batch_size controla el throughput vs VRAM
embeddings = model.encode(
chunks,
batch_size=32,
normalize_embeddings=True,
show_progress_bar=True
)
print(f"Shape: {embeddings.shape}") # (3, 1024)
print(f"Norma del primer vector: {np.linalg.norm(embeddings[0]):.4f}") # ~1.0 por la normalización
Code block 3: comparativa de similitud entre frases en español
import numpy as np
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-m3")
frases = [
"cancelar suscripción al servicio", # query
"dar de baja el contrato", # paráfrase semántica
"eliminar cuenta de usuario", # cercana pero diferente
"renovar el plan anual", # opuesta en intent
"precio del servicio mensual", # relacionada, distinta tarea
]
embeddings = model.encode(frases, normalize_embeddings=True)
query_emb = embeddings[0]
candidatos = embeddings[1:]
def cosine_sim(a: np.ndarray, b: np.ndarray) -> float:
"""Con vectores L2-normalizados, es simplemente el dot product."""
return float(np.dot(a, b))
print("Similitud coseno respecto a 'cancelar suscripción':\n")
for frase, emb in zip(frases[1:], candidatos):
score = cosine_sim(query_emb, emb)
print(f" {score:.4f} → {frase}")
# Salida esperada (aproximada):
# 0.8934 → dar de baja el contrato (alta similitud semántica)
# 0.7421 → eliminar cuenta de usuario
# 0.3821 → renovar el plan anual (intención opuesta)
# 0.5102 → precio del servicio mensual
Este bloque ilustra el comportamiento clave: «cancelar suscripción» y «dar de baja el contrato» obtienen alta similitud coseno aunque no compartan ningún token. Un sistema BM25 clásico devolvería similitud cero entre esas dos frases. Es la diferencia operativa que justifica el uso de embeddings en cualquier sistema de búsqueda sobre lenguaje natural.
Fine-tuning de embeddings con tu propio dataset
Cuando un modelo generalista no alcanza la precisión necesaria en tu dominio, el fine-tuning es la siguiente palanca. No requiere datos masivos: con 500-2000 pares etiquetados bien construidos, el modelo puede aprender la semántica específica de tu corpus.
Qué datos necesitas para el fine-tuning
El fine-tuning de un modelo de embeddings requiere pares de entrenamiento con etiqueta de similitud. Los formatos más comunes son: pares positivos (dos textos semánticamente equivalentes), tripletas (anchor, positivo, negativo), y pares con score continuo (0-1). La forma más eficiente de generar datos de entrenamiento sin etiquetado manual masivo es synthetic data generation: dado un corpus de documentos, usar un LLM para generar preguntas que cada chunk respondería. El par (pregunta generada, chunk original) es un par positivo. Esto puede producir miles de pares de entrenamiento en horas con coste mínimo.
Code block 4: fine-tuning con SentenceTransformer.fit()
from sentence_transformers import SentenceTransformer, InputExample, losses
from sentence_transformers.evaluation import InformationRetrievalEvaluator
from torch.utils.data import DataLoader
# Pares de entrenamiento: (anchor, positivo)
# Generados sintéticamente con un LLM o etiquetados manualmente
train_examples = [
InputExample(texts=[
"¿Cuándo se puede cancelar el contrato sin penalización?",
"El contrato puede resolverse sin cargo si se notifica con 30 días de antelación."
]),
InputExample(texts=[
"¿Cuál es el plazo de devolución del producto?",
"Los productos pueden devolverse en un plazo de 14 días desde la recepción."
]),
# ... mínimo 500 pares para resultados relevantes
]
model = SentenceTransformer("BAAI/bge-m3")
# MultipleNegativesRankingLoss: trata el resto del batch como negativos
# Es eficiente en memoria y funciona bien con pares positivos únicamente
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
train_loss = losses.MultipleNegativesRankingLoss(model)
# Evaluador opcional: mide Recall@10 en un conjunto de validación
# Requiere un dict {query_id: query_text} y {doc_id: doc_text} + relevances
# evaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs)
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=3,
warmup_steps=100,
output_path="./finetuned-bge-m3-legal-es", # guardar el modelo
show_progress_bar=True,
# evaluator=evaluator, # descomentar para evaluación en cada epoch
# evaluation_steps=500,
)
print("Fine-tuning completado. Modelo guardado en ./finetuned-bge-m3-legal-es")
# Cargar de vuelta:
# model_ft = SentenceTransformer("./finetuned-bge-m3-legal-es")
El fine-tuning con MultipleNegativesRankingLoss es la opción preferida cuando solo tienes pares positivos porque convierte automáticamente los otros ejemplos del batch en negativos implícitos. Con un dataset de 1000 pares y 3 epochs sobre BGE-M3, es realista esperar una mejora de 5-15 puntos en Recall@10 en el dominio específico, dependiendo de cuánto difiere tu corpus del entrenamiento original del modelo. En Baigency usamos este enfoque para agentes de IA empresariales que necesitan búsqueda precisa sobre documentación interna con jerga específica del sector del cliente.
Para dominar el resto del pipeline —desde la estrategia de chunking hasta la indexación en una base de datos vectorial y la orquestación con el framework LangChain— los posts laterales del cluster cubren cada componente en detalle. El post de RAG en Python integra todos los componentes en un pipeline completo.
Preguntas frecuentes sobre embeddings
¿Cuál es la diferencia entre un embedding y un vector?
Un vector es una estructura matemática: un array ordenado de números. Un embedding es un vector con una propiedad adicional: ha sido generado por un modelo entrenado para que la posición en el espacio vectorial tenga significado semántico. No todo vector es un embedding, pero todo embedding es un vector. En la práctica del día a día en ML, los dos términos se usan indistintamente cuando se habla de representaciones de texto, imágenes o código generadas por un modelo. La distinción importa cuando se discute la arquitectura: el embedding es el resultado de un proceso de aprendizaje, no un mapeo arbitrario.
¿Cuántos tokens soporta un modelo de embeddings?
Depende del modelo. text-embedding-3 (OpenAI) admite hasta 8191 tokens. BGE-M3 llega a 8192 tokens. voyage-3 soporta 32.000 tokens. Los modelos más antiguos como all-MiniLM-L6-v2 tienen un límite de 512 tokens. Cuando un texto supera el límite, el modelo trunca silenciosamente o lanza un error dependiendo de la implementación. Para documentos largos, la estrategia correcta es el chunking previo: dividir en fragmentos que quepan cómodamente dentro del contexto del modelo, con superposición entre chunks para no cortar ideas a mitad.
¿Por qué cosine similarity y no distancia euclidiana?
En espacios de alta dimensión (512+ dimensiones), la distancia euclidiana sufre la maldición de la dimensionalidad: las distancias entre puntos se homogenizan y pierden poder discriminativo. Además, la distancia euclidiana es sensible a la magnitud del vector, lo que puede penalizar documentos más cortos aunque sean más relevantes. La similitud coseno es invariante a la escala y mide ángulo puro, que en embeddings semánticos correlaciona mejor con la similitud de significado. Con vectores L2-normalizados, cosine y dot product son equivalentes, permitiendo usar optimizaciones SIMD de product quantization sin sacrificar calidad semántica.
¿Es mejor un modelo de embeddings open-source o de pago?
Depende de tres factores: soberanía de datos, coste a escala y requisitos de calidad. Si los datos son confidenciales o están sujetos a regulación (sanidad, banca, administración pública), open-source es la única opción porque los datos nunca salen de tu infraestructura. En coste, los modelos locales tienen coste marginal cero una vez amortizado el hardware, ventajoso a partir de ~50M tokens/mes. En calidad, modelos como E5-mistral-7b o BGE-M3 son competitivos con los propietarios en benchmarks, aunque los modelos de Voyage superan al open-source en retrieval inglés. La elección no es binaria: muchos sistemas usan open-source para pre-filtrado y un modelo de pago para reranking.
¿Cuántos datos necesito para hacer fine-tuning de un modelo de embeddings?
Con 500-2000 pares positivos bien construidos es suficiente para ver mejoras reales en un dominio específico usando MultipleNegativesRankingLoss. La calidad de los pares importa más que la cantidad. El método más eficiente para generar datos de fine-tuning sin etiquetado manual es la generación sintética: dado un corpus, usar un LLM para generar preguntas que cada fragmento respondería. El par (pregunta, fragmento) es un par positivo válido. Con GPT-4o mini y 1000 chunks, puedes generar 5000 pares en menos de una hora y por menos de 5 euros. El modelo fine-tuneado puede desplegarse localmente, eliminando el coste de API en producción.
¿Qué es Matryoshka Representation Learning y para qué sirve?
Matryoshka Representation Learning (MRL) es una técnica de entrenamiento donde el modelo aprende a representar la información más importante en las primeras dimensiones del vector, de modo que una versión truncada del embedding (por ejemplo, los primeros 512 valores de un vector de 3072) sigue siendo semánticamente útil. OpenAI la implementa en text-embedding-3, permitiendo especificar el parámetro dimensions en la llamada API y recibir un vector reducido sin reentrenar el modelo. Esto es valioso en producción: puedes empezar con 1536 dimensiones para balancear calidad/coste, y reducir a 512 si la latencia o el almacenamiento se convierten en un cuello de botella, sin invalidar los embeddings ya generados.
Conclusión
Los embeddings son la pieza que convierte texto arbitrario en algo que un sistema puede razonar de forma cuantitativa. Sin una capa de embedding de calidad, un pipeline RAG es tan bueno como una búsqueda por palabras clave del año 2005. Con el modelo correcto, la métrica de similitud adecuada y una estrategia de fine-tuning cuando el dominio lo requiere, el retrieval semántico puede superar el 90% de precision@5 incluso sobre corpus complejos en español.
El mapa es claro: para producción general en español, text-embedding-3-large o BGE-M3. Para retrieval de alta precisión en inglés, voyage-3. Para soberanía de datos, BGE-M3 o E5-mistral-7b desplegados en tu propia infraestructura. Para dominios muy específicos, fine-tuning con MultipleNegativesRankingLoss sobre datos sintéticos generados con un LLM. Y siempre, cosine similarity como métrica base salvo que midas una razón clara para cambiarla.
Si estás construyendo un sistema RAG para documentación interna, un agente de IA con memoria sobre contratos o un motor de búsqueda semántica para tu ecommerce, la elección del modelo de embeddings es una decisión arquitectónica que impacta coste, latencia y calidad de forma permanente. En Baigency evaluamos esta decisión en la fase de consultoría técnica antes de escribir una línea de código. Si quieres hablar sobre cuál es el modelo correcto para tu caso, el formulario de contacto está abajo.
El siguiente paso natural es integrar estos embeddings con una base de datos vectorial eficiente, diseñar la estrategia de fragmentación de documentos, y orquestar todo desde un framework LangChain o implementar RAG completo en Python. Para arquitecturas más complejas con agentes con estado, LangGraph añade el grafo de control que los embeddings solos no pueden proveer. Y para sistemas de agentes de IA para empresas en producción, la integración de embeddings es solo el primer componente de una arquitectura que necesita observabilidad, evals y gestión de versiones del índice.